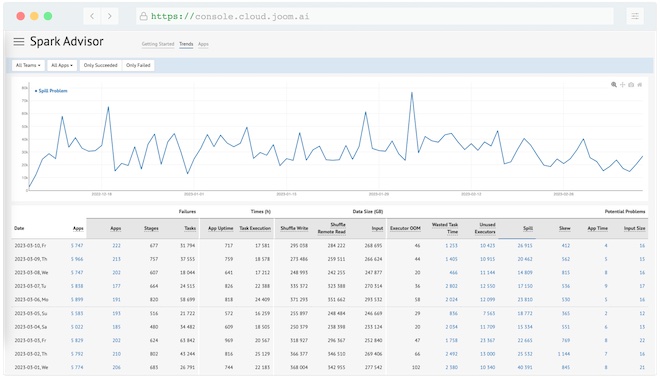
- Spill — when you're out of execution memory
- Excessive retries — when the data is recomputed all over
- Unused executors — when the driver is doing too much
- Several more now, even more coming in future
Spark Performance Advisor
Automatically detect performance issues in all your Spark jobs